

Please note: this article is part of the older "Objective-C era" on Cocoa with Love. I don't keep these articles up-to-date; please be wary of broken code or potentially out-of-date information. Read "A new era for Cocoa with Love" for more.
I was recently asked by a reader if I used any modelling program to model the classes and relationships in my Mac applications. The answer is no, I don't model the application side of my programs. The reason for this is not because applications are always small and simple. The reason is that all applications have approximately the same design — eventually everything in a well-designed application becomes intuitive.
Ontology
It would be a mis-statement to claim that all applications have the same design but it is accurate (although more confusing) to state that all well-designed applications share a very high degree of ontological similarity.
Ontology is a pretty obscure word so it might be a good idea to explain it here. I'm going to use an analogy...
When you have a lot of items, it's helpful to classify them into a structure to understand how they relate to each other. For example: all living species on Earth are classifed into Domain, Kingdom, Phylum, Class, Order, Family, Genus and Species. We often just talk about animal or plant "species" but the classification system has many more levels (in fact, there are many more levels in-between these simple names that I've listed). The classification of living things is an example of a "taxonomy" (classifying things into a single hierarchy).
Similarly, every class in a well-designed application can be classified. But the classification of an application isn't a simple tree structure — there are many different connections. And the connections aren't simply of heredity — there are subclasses, view hierarchies, event hierarchies, control hierarchies and more.
When each classified element may have more than one position in the tree, and when different connections may have different semantic meanings and the overall organization isn't a simple tree but it's more of a big ball of wibbly-wobbly, interconnected stuff — that's an ontology.
The ontology of an application
Due to the interconnected, non-simple structure of ontologies, it's difficult to give a simple diagram that fully models one. Instead, I'm just going to list the broad categories of classes that you find in an application and simply discuss how they actually interconnect.
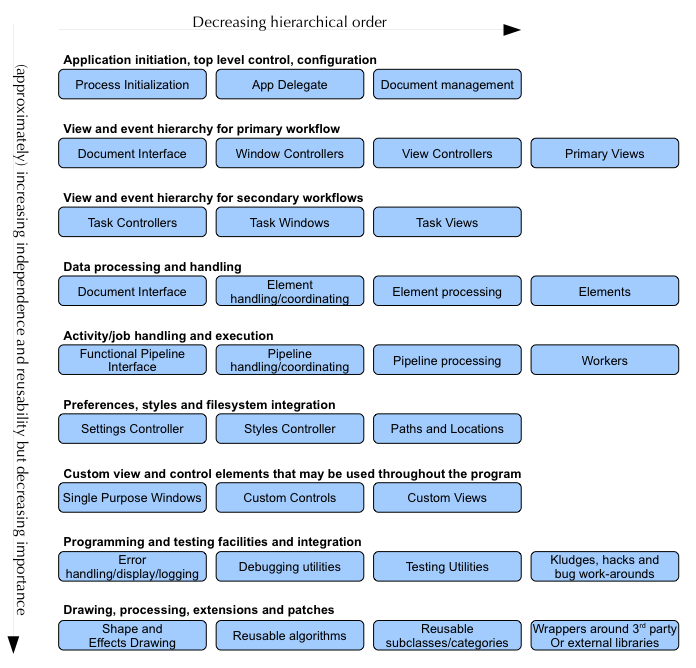
The basic categories of class in an application ontology.
This diagram describes pretty much every class type you're likely to see in an application. In a well designed project, these are the names of the Groups in the class tree.
Where did I get this list? I've really just transcribed the Groups from some of my larger projects. If you're interested, I consider a large project to be approximately a couple hundred classes. The largest I've ever let a project get is just over 400 classes. Normally, as a project gets near that size, I break it apart into multiple sub-projects. Generally, in a break apart like this, the "application" stays where it is and the "document" or "job handler" components get spun out into their own projects.
Breaking a huge project into pieces offers lots of advantages: it makes building faster, forces better abstraction and interfaces and makes testing easier (because the interface between components is a great place for system tests). The drawback is that the build process and version management can get a little trickier but once the project becomes that big, you normally have a good process in place to handle that complexity.
Applications on other platforms: While applications on different operating systems share much in common, the description here applies most accurately to Cocoa Mac applications. The needs of interacting with different application frameworks and delivering different features to users on different platforms ultimately effect the ontological structure of the application's classes.
Application initiation, top level control, configuration
In a Cocoa program, this includes the main.c file and your App Delegate. In a Cocoa Mac document-based application, this also includes the NSDocumentController.
These classes perform startup and top-level handling and shouldn't do anything else.
A good indication of a hastily or poorly written application is when other functionality gets implemented in one of these classes. Since these classes are almost always present and are accessible at the top level, it's easy to be lazy and shove functionality into them because the functionality doesn't seem to fit elsewhere.
View and event hierarchies for primary workflow
This includes your primary NSDocument subclass, your NSWindowContorllers, NSViewControllers, UIViewControllers and the primary (used for displaying the main document) NSViews or UIViews.
In a simple application that does more browsing than processing, this will be the bulk of the project. Fortunately, the view hierarchy is typically highly structured. Controllers at the top and nested views all the way down.
New communication between view elements should go through the top controller of any hierarchy or should through connections established by a higher level of the hierarchy. Views talk to corresponding document objects but the correspondence should be entirely established by the controllers.
The view and event hierarchies are generally similar; the few differences there are likely to be will rarely cause a problem.
View and event hierarchies for secondary workflows
An example of a secondary workflow would be the downloading interface in a web browser — a fully contained user-interface that runs in a different view or window. It also includes complicated popup/modal or other interfaces like the "Get Info" interface in the Mac OS X Finder or the "Add to Playlist" functionality in the iPod app on the iPhone.
These tend to run like separate little programs within the greater application and you should write them as such. While they may share some views and data with the rest of the program, they generally use their own controllers to manage the workflow and as such should not simply be lumped in with the classes from the main workflow.
Data processing and handling
This is your "document" (or "model" in MVC parlance). In a basic application, the document may be vanishingly small (a single array of objects or even a single object). For the largest applications though, the document is generally the majority of the program.
Generally, the document includes an interface at the top level that connects it to the structure of the rest of the program — since the elements within the document should be as ignorant of the structure of the rest of the program as possible. This connective interface is sometimes rolled into the NSDocument class on the Mac (which is also the controller of the document's view hierarchy). That's not too bad (they're both controllers) but in larger programs, the connecting controller for the document's view and the document's model may end up being different classes.
Below the interface there is normally some form of management or coordination to handle caching, saving, memory and other issues related to the runtime state but not necessarily the persistent state of the document. This is the role that the NSManagedObjectContext performs for a document implemented using Core Data.
Since the document is the part of a program that is not inherently designed following "application" rules, it does not necessarily follow an application ontology. For this reason, you may need to keep diagrams to understand the structure of highly complex document model. Fortunately, if you're using Core Data or another persistence framework for storing your model, you probably already have a diagram of your model.
Activity/job handling and execution
This is a category that unfortunately gets left out of many MVC discussions.
A functional pipeline fulfils a similar role to the document but instead of exposing data storage and manipulation to the user, exposes actions and behaviors.
An example would be a web server. If you push the "Start Server" button in your user interface, that button is not connected to a document but to a top level controller that starts the server. That top-level controller is the interface to a functional pipeline.
In many respects, a functional pipeline should be treated like a document — connect it to views in the same way (through controllers that link values to display) and manage it in the same way (through a top level interface that exposes functionality to the rest of the program).
Preferences, styles and filesystem integration
This layer is largely filled with singletons; independent components that manage a small set of data that can be accessed at will from anywhere in the program.
These types of classes tend to drive Dependency Injection enthusiast Unit Testers crazy because they follow a state-machine rather than a command-pattern (state machines are very hard to unit test).
Settings management is an essential component of larger programs. Basic storage provided by NSUserDefaults becomes insufficient once different parts of the program need to coordinate access to the same settings.
A styles controller is really just a way of accessing the same fonts, colors and other elements that make your program look consistent.
Custom views and control elements
This level is the storage bin for controls and views that are not tied to a specific workflow but (like the Styles Controller) are reused through the program to give a consistent aesthetic and set of behaviors to the use.
Single purpose views generally live along with the workflow that uses them. For this reason, as a program goes, you may continuously generalize your single use views and move them out of a workflow into this more general section.
This level of the application ontology also tends to be the first so far that contains concrete classes that may be brought in from outside the program. While your view controllers or document may include reusable abstract classes, the concrete implementations are normally specific to your program. Custom controls however are easily used in concrete form across a range of different applications.
Programming and testing facilities and integration
This is the cluster of classes that the user should never see (with the possible exception of Error dialogs). Many of the debugging and testing classes simply don't appear in release builds.
Why would kludges, hacks and bug work-arounds appear here instead of closer to the classes they affect? Because they are parts of your code that the developer needs to keep a close eye on and should be able to disable easily in the event that they no longer apply. For these reasons, you should keep them from directly polluting your real code.
Drawing, processing, extensions and patches
These are the type of class that I've shared many times in this blog: handy tricks for accessing or achieving something with little or no dependency on the rest of your application.
While this occupies just a single level of the diagram, in a medium sized program, these classes could be more than half the total classes in the program — little tools, tricks, reusable code and behaviors you like to carry from program to program.
Fortunately, the large number of these classes rarely makes the program more complex — they have no significant connections to the rest of the program. The only difficulty tends to be cleaning them out when they're no longer used.
Scalability
In many situations, the size of a program increases complexity and makes it harder to understand.
For the "application" side of a program (not including the "document"), greater size actually tends to force the program to behave more regularly and fit the categories I've discussed better.
In smaller applications, classes tend to be more multi-functional, spanning many of these categories. As an application grows, classes tend to become more single-functional so they fit the standard categories better.
The "document" — and to a lesser extent, functional workflows — tend to be the exception to this scalability rule, since they don't adhere to a common ontology. You will probably want to model and document your document.
Conclusion
Applications are a relatively narrow domain within programming overall — they need to perform specific functions and tend to perform those functions in similar ways.
This similarity leads them to be structure similarly, to interconnect in similar ways; to share a common ontology.
While the pattern may not be obvious when looking at a large program for the first time, or if you're continuously looking at hastily-constructed, small-to-medium sized projects, applications are structurally simple.
I've drawn a distinction in this post between applications and other types of programs — even between the application part of a program and the non-application parts of a program. Obviously, non-application parts of an application will likely not follow the ontology of an application.
While a badly designed, badly organized project can escape many of the traits you'd normally expect from an application, the mechanics of hooking into a framework like Cocoa and required steps to implement application-like features still dictate a structure that is hard to escape.
Sorting an NSMutableArray with a random comparison method